TLDR
I created SocratesGPT to test the concept of using AI to generate questions about a given topic. Its goal you learn topics better by asking you questions about it. I also provide some technical details on the implementation.
Why?
Over a year ago, I began using Anki, a spaced repetition flashcard app that helps me retain information over the long term by taking advantage of the Ebbinghaus forgetting curve. Memory is like a leaky bucket, and it was incredibly frustrating to realize I’d forgotten most of what I learned. Anki has enabled me to confidently tackle difficult technical topics that I would have otherwise avoided.
One issue with Anki is that you can start to “overfit” on the questions you wrote. With Anki, you look at the card and then check the answer after trying to recall it. Once you’ve seen the answer, you rate how easily you were able to recall it, which determines when the question will reappear in your deck. Creating questions can be time consuming, so I’ve found that most of my cards end up being “cloze deletions”, i.e. fill-in-the-blank. This increases the risk of memorizing the answer to the card rather than truly understanding the concept.
What if we could use AI to help us understand a topic better?
SocratesGPT
Unless you’ve been living under a particularly forlorn boulder, you’ve heard about ChatGPT. You may not know that you can access GPT-3.5 as an API. The most advanced model available via OpenAI’s API is gpt-3.5-turbo. This space is moving fast. When I started this project, the most advanced model was text-davinci-003 which was 10x more expensive and somewhat slower. Edit: now GPT-4 is out.
GPT (generative pre-trained transformer) is a type of “large language model” (LLM) (sorry about the acronyms). By using “prompt engineering”, you can have the model return a structured JSON output for a given prompt, which can then be rendered in a UI. This means the app’s “backend” can consist of a single prompt.
I saw a great example of this at https://github.com/varunshenoy/GraphGPT. It shows an example of using one-shot prompting to teach GPT to give a JSON structured response. I was surprised to find that this style of prompting always gives back valid JSON, assuming you also set the model parameters appropriately.
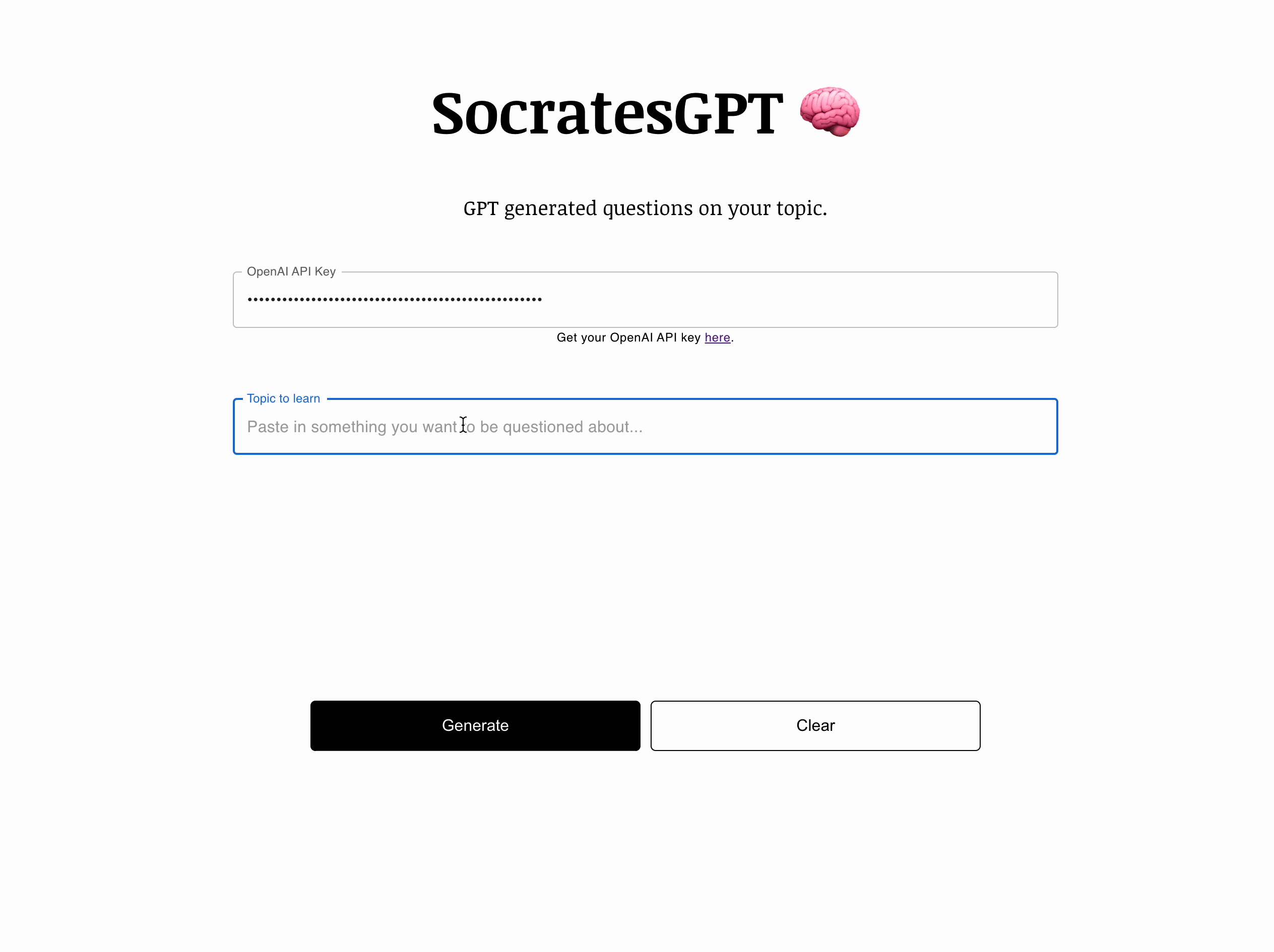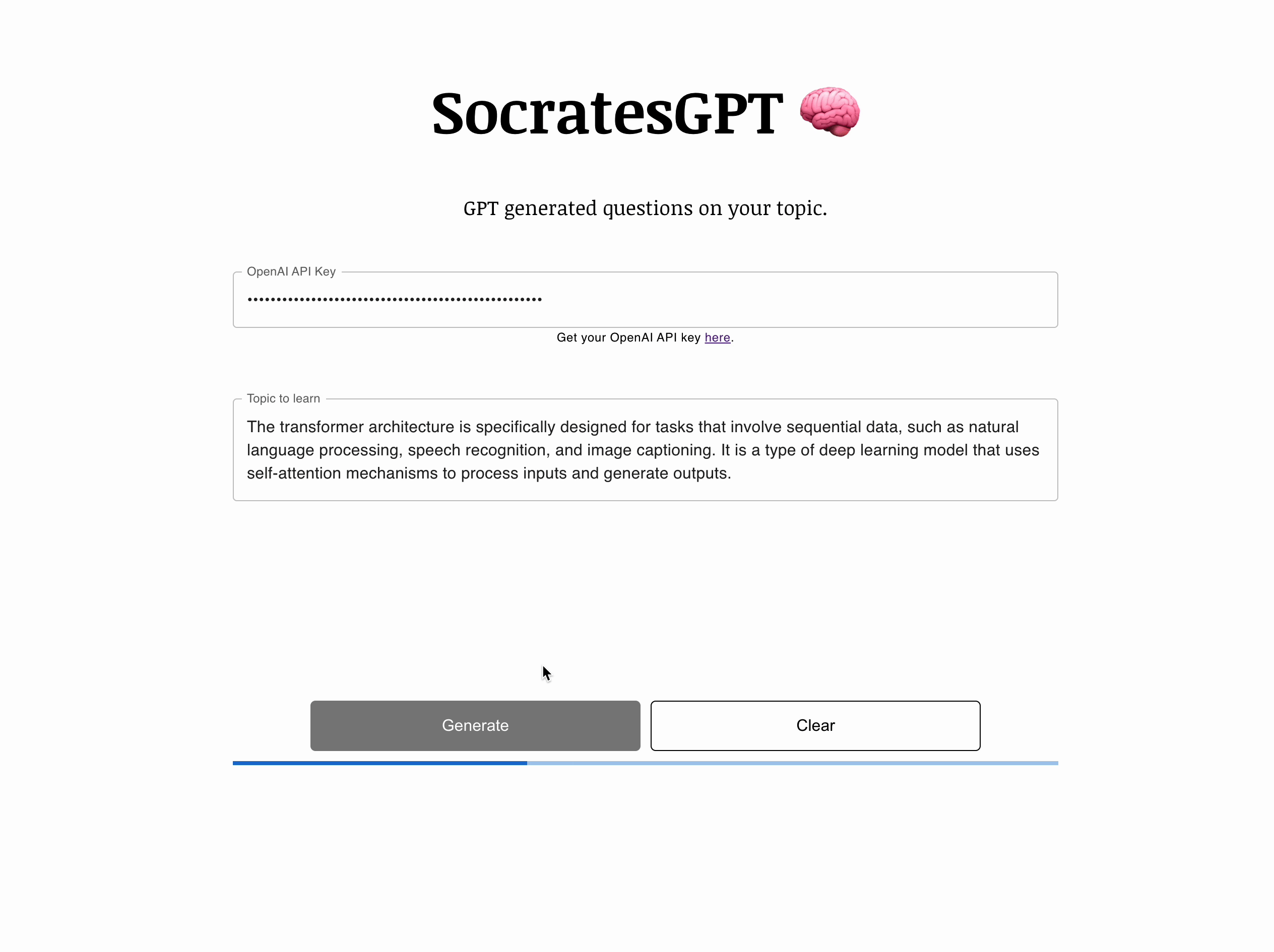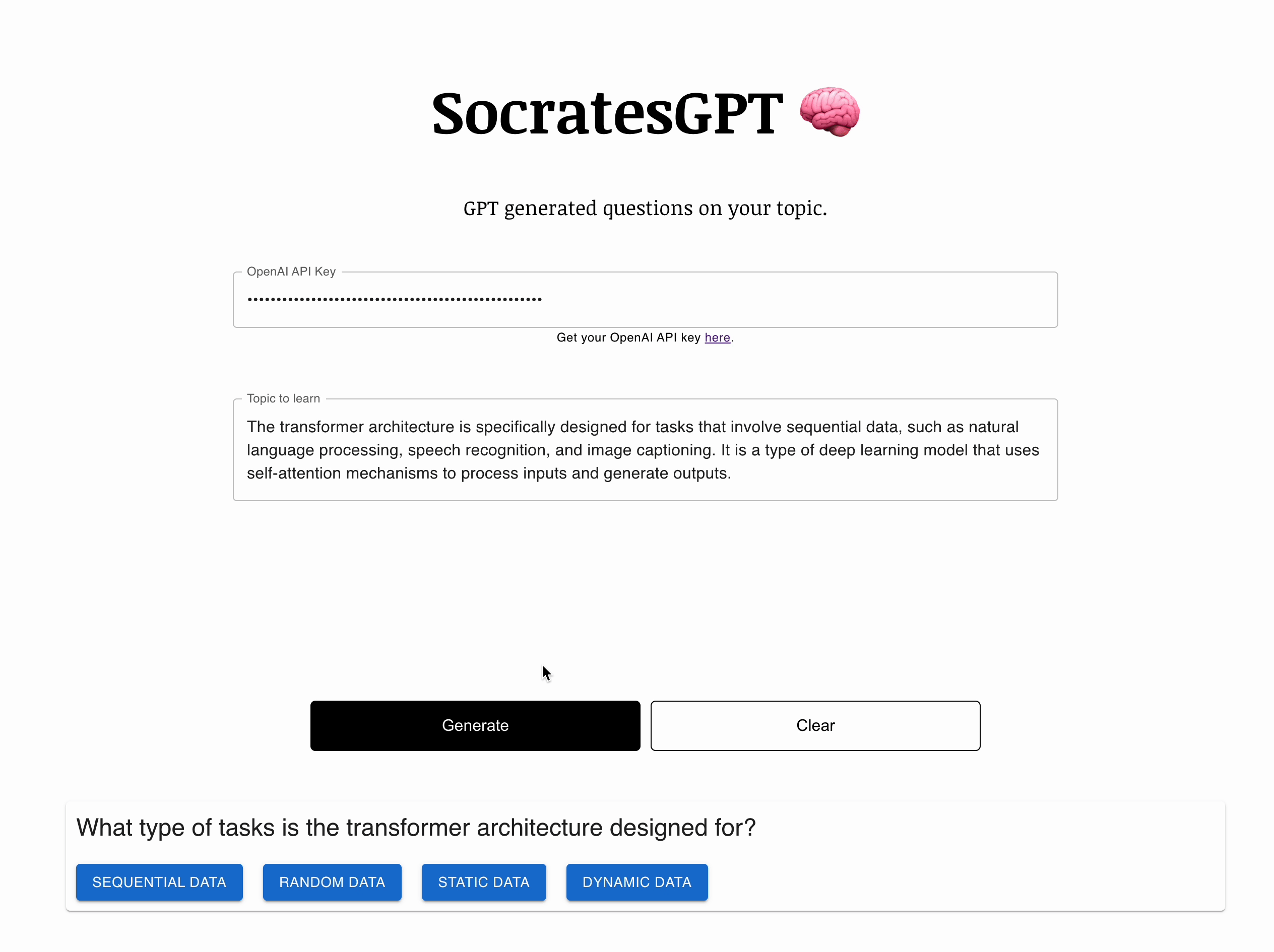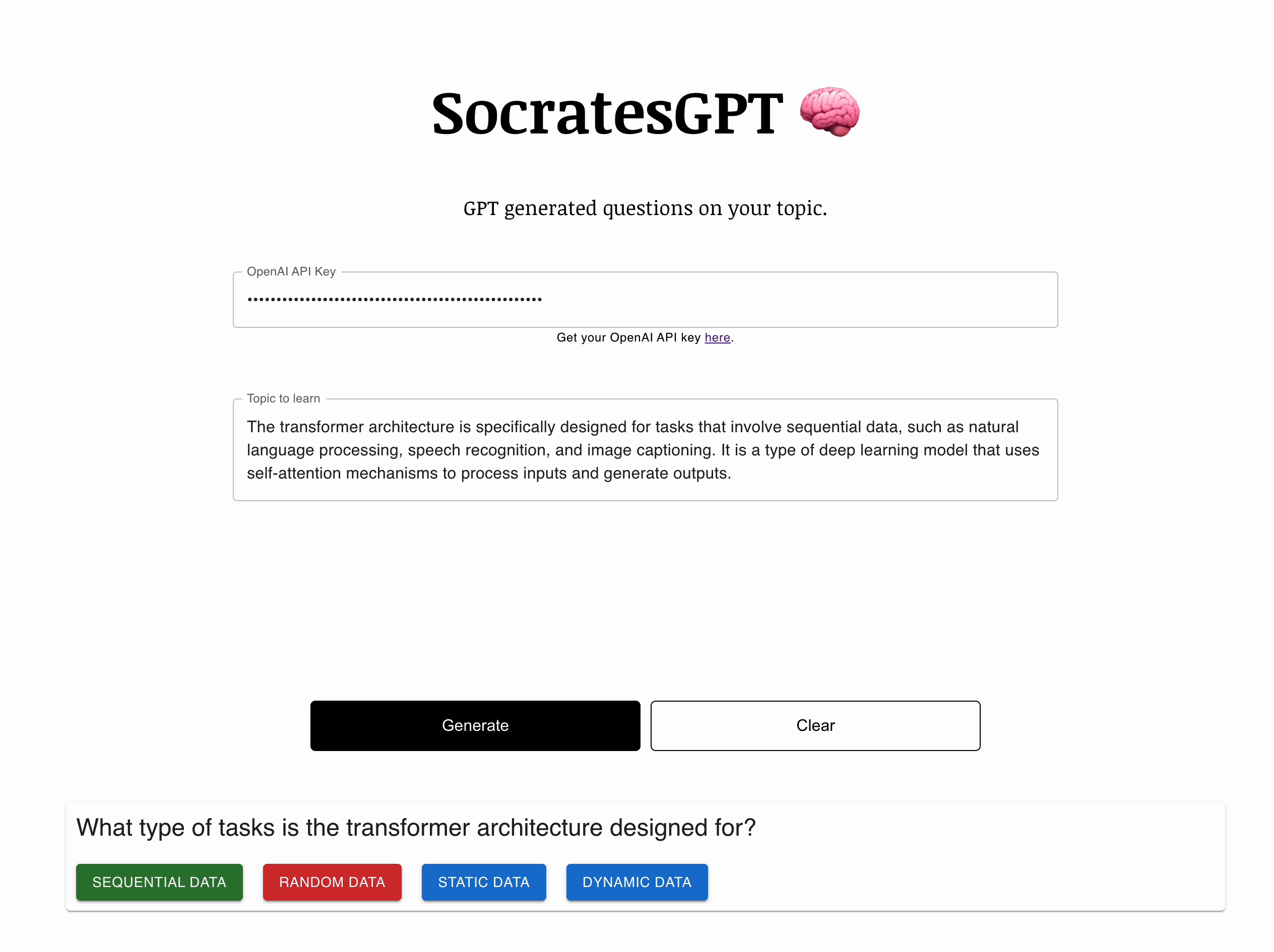
I created SocratesGPT to test the concept of using AI to generate questions about a given text. The Socratic method is a questioning style that encourages students to discover their beliefs and uncover hidden assumptions. However, SocratesGPT does not fully follow the Socratic style, as there is no real dialogue between student and teacher. The name is more aspirational than descriptive.
In my prompt, I ask the model to impersonate Socrates, and generate questions based on the given text. I also provide an example of the expected response in JSON format. The React front end parses the JSON and renders it. If you ask for another question, the app updates the prompt with the previous state of questions and options selected and pass it back to the model.
Creating a traditional backend to power an app like this without the use of LLMs would be highly non-trivial.
“Prompt Engineering”
Prompt engineering is the process of designing effective prompts for large language models such as GPT. Effective prompts are more likely to elicit high-quality outputs. Garbage prompt in, garbage response from the LLM.
I started with a fairly simple prompt:
You are impersonating a question generator using the socratic method.
You will be given a prompt, and you must respond with a question about that prompt.
The response must be a valid json object with the following fields:
prompt, question, answer, and correct.
Eventually I had to add the following lines to get a cleaner response:
You cannot ask the same question twice.
Try to limit the number of words in the choices to 4.
If a choice is selected, it should be marked as selected: true.
If a choice is not selected, it should be marked as selected: false.
I had the feeling of training an overly eager genie when phrasing my prompt. When you ask a genie to stop the trolley from hitting the pedestrian, the genie might find blowing up the trolley to be a perfectly reasonable solution. So you end up adding additional clauses: “err, also don’t blow it up!”.
This is followed by a one-shot training example, where I provide a single example of what I want the model to do. I provide a starting state with my initial data structure:
Examples:
current state:
{
"counter": 1,
"prompt": "",
"questions": [{}]
}
prompt is the text the model should generate questions on. questions is an array of question objects.
Then I show an example prompt, and the expected response from the model:
prompt: The sky is blue.
new state:
{
"counter": 1,
"prompt": "The sky is blue.",
"questions": [{
"question": "What color is the sky?",
"choices": [{
"text": "blue",
"correct": true,
"selected": false
}, {
"text": "red",
"correct": false,
"selected": false
}, {
"text": "green",
"correct": false,
"selected": false
}, {
"text": "yellow",
"correct": false,
"selected": false
}]
}]
}
Each question includes the generated question, along with an array of choices. The selected boolean is used in the front end to maintain the state of which options the user clicked, so these aren’t lost when a new prompt is generated.
Finally we create a way for us to dynamically update the prompt:
current state: $state
prompt: $prompt
new state:
In the front end, we inject the current state into $state and the prompt into $prompt:
fetch("prompts/data.prompt")
.then((response) => response.text())
.then((text) => text.replace("$prompt", prompt))
.then((text) => text.replace("$state", JSON.stringify(state)))
We have some control over the parameters of the model, such as the temperature, max tokens, and top p. I found that the model works best when the temperature is set to 0.3. Temperature controls the “creativity” of the model. A lower temperature means the model is more likely to generate correct, almost deterministic responses. A higher temperature means the model generally leads to creative responses. frequency_penalty sets a penalty for repeating words. presence_penalty sets a penalty for repeating n-grams. top_p sets the probability mass function cutoff.
const DEFAULT_PARAMS = {
model: "gpt-3.5-turbo",
temperature: 0.3,
max_tokens: 800,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
};
After the user clicks “Generate Question”, the value of $prompt is obtained from the prompt text area in the UI. The $state starts as a skeleton of the data structure provided in the training example. We call OpenAI’s new gpt-3.5-turbo chat completions API with data.prompt. The JSON response contained in data.choices[0].message.content is parsed to update the state and render the question in the UI.
I found that the prompt in the new API needs to use single quotes instead of quotes when sent to the model, and then I have to replace the single quotes in the response with double quotes again to make it valid JSON. There’s probably a cleaner way to do this. I also feed the entire prompt as the role user, but some parts of it may be better suited to the system role.
const params = {
...DEFAULT_PARAMS,
messages: [{ role: "user", content: prompt }],
};
...
const requestOptions = {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: "Bearer " + String(apiKey || OPENAI_API_KEY),
},
body: JSON.stringify(params),
};
fetch("https://api.openai.com/v1/chat/completions", requestOptions)
.then((response) => response.json())
.then((data) => {
const text = data.choices[0].message.content;
// replace ' with " to make it valid JSON
const new_state = JSON.parse(text.replace(/'/g, '"'));
setState(new_state);
If the user generates another question, we pass in the $state which now includes the first question. This lets the model we know what it already asked.
Limitations
There are several limitations with the current implementation:
- When providing very short input text, the model may generate questions that are not grounded in the text. For example, if the input text is “The sky is blue”, the model may generate a question like “Why is the sky blue?” even though the reason is not provided in the text. This is related to the “grounding problem”, which is one of the major flaws of LLMs. Shorter input text provides less grounding, thus allowing for more hallucinations.
- Occasionally, the model seems to “undo” changes in state. For example, a question might get removed from state on the next run.
- It can take up to 20 seconds to receive a response from the API. The response time seems to increase with the size of the prompt. This can make it less engaging. Newer versions of the OpenAI API will likely have faster response times.
- Setting
frequency_penaltyandpresense_penaltyparameters to1seems to result in invalid JSON. This might be because they make the model less likely to generate characters like{multiple times, which is required for the JSON to be valid.
Future
There’s a few ways SocratesGPT could be improved. Users could be able to save questions, and later be quizzed on them using spaced repetition. Larger context windows would allow the model to create questions on entire books. Eventually, GPT could be “fine-tuned” to ask more effective questions. You might even be able to implement reinforcement learning from human feedback (RLHF). Students could rate the quality of questions, which is then fed back into the model.
As multi-modal models mature, the AI could even generate diagrams, such as an image of a section of the brain with an arrow pointing to the area that the user is asked to label. Finally, the grounding problem should be addressed to prevent the model from “hallucinating” questions that are not in the input text.
The “T” in GPT stands for transformer, which is currently the most powerful deep learning architecture for several tasks, including NLP. There will likely be better architectures in the future. As the cost of GPU compute decreases, larger models with many more parameters become possible. By building on improvements like these, we can create ever more advanced AI tutors. These tutors will be able to understand your learning goals and current understanding to create personalized curriculums that are just difficult enough to challenge and ensure long term retention.
Advancing AI can help close the gap that MOOCs currently have difficulty filling, and help to scale education. Increased education leads to more people with advanced degrees that can help us solve some of our most pressing challenges. These are still the early days of LLMs.